Aladeen is a read-only TypeScript pipeline that turns the logs five different agent CLIs already write to disk into one queryable model of what keeps going wrong. It ingests Claude Code, opencode, Codex, OpenClaw, and its own engine's runs, normalizes two genuinely different storage shapes (per-session JSONL and a relational SQLite database) onto a single Zod-validated SessionTrace, content-addresses every run by a failure fingerprint, and surfaces citation-backed remedies without ever running the agent itself. The motivating problem is that you can run Claude Code two hundred times and have no idea which failures recur, because every agent CLI keeps almost everything about a session and exposes almost nothing. The hardest part wasn't reading the logs. It was the schema waist and the honesty machine on top of it: a learning layer where the truthful answer ("I have nothing comparable") is the cheapest path through the code, not a disclaimer bolted on after.
The problem
Every major lab shipped a coding CLI in 2024 and 2025, and they share one flaw: they throw away almost nothing about a session yet expose almost nothing about what they keep. The data is right there on disk, in incompatible shapes: ~/.claude/projects/<cwd>/*.jsonl, opencode's opencode.db SQLite store, Codex's ~/.codex/sessions/YYYY/MM/DD/rollout-*.jsonl. None of them ship a way to ask "what keeps going wrong here?" You either re-read two hundred JSONL transcripts by hand or you stay blind.
The crowded answer to "make agents better" is orchestration: Conductor, Vibe Kanban, Claude Squad, opencode itself, all trying to drive the agent. I bet the opposite, and deliberately narrow: don't replace your agent, learn from it. The orchestrator category is saturated; observability for CLI-based agents was empty. The honest backstory is that Aladeen started as an orchestrator, a DAG blueprint runner with git-worktree isolation, and I demoted it on purpose. The runner survives only because its own ExecutionState is the fifth ingestible source, which closes an observability loop: the engine that runs agents becomes one more thing the observability core reads.
Constraints
Solo build, zero budget, has to run anywhere. That last constraint did most of the architectural work. The core observability path must be pure-JS with no native dependencies, so npx aladeen report works on any Node 20+ machine without a compile step. The tool is read-only by mandate: it suggests, it never executes, because the moment it runs a fix it becomes the orchestrator I just stopped building, the saturated category it differentiated away from.
The other hard line is privacy. Raw secrets and PII must never touch disk. That is not theoretical: there was a real secret-leak incident on this repo, documented in docs/security/SECRET-INCIDENT-REMEDIATION.md, which is why scrubbing happens at the ingest boundary, and why gitleaks plus a CI secret-scan workflow sit behind it as defense-in-depth: three independent layers, because one in-process pass is a single point of failure.
Architecture: a hard schema waist
Aladeen is a classic ETL shape repurposed for agent telemetry. Source-specific Extractors read each CLI's native store. A Transform stage projects every shape onto one SessionTrace, scrubbed and seq-ordered at the boundary. A Load stage writes the trace plus a derived RunDigest to a flat content-addressable-by-id file store under .aladeen/ingested/. On top of the digest store sit four read paths (terminal report, markdown replay, tiered remedy, MCP server) plus the demoted blueprint engine whose runs feed back in as a fifth source.
The whole system pivots on one boundary: SessionTraceSchema.safeParse. Everything upstream of it is source-aware; everything downstream is source-blind. That is the normalization boundary in the database sense: a single canonical model that the report, the classifier, the failure miner, and the remedy engine all consume without ever branching on which CLI produced a session. The README states the invariant plainly: the JSONL and SQLite ingesters "look completely different on the inside and produce identical SessionTrace output." Adding a sixth CLI is an additive change: extend the 7-member SourceKind union and write one adapter. No schema migration, no consumer touched.
Strict typing carries the load-bearing SessionTrace schema; the Node 20 floor keeps the core pure-JS so npx runs anywhere with no compile step.
SessionTrace and RunDigest are Zod schemas safeParse-d at every ingest boundary; a z.discriminatedUnion models the 9 event kinds as a closed sum type.
Ships aladeen-mcp over stdio: 3 read-only tools + 2 resources returning dual-channel (human markdown + machine structuredContent), no network, one .mcp.json entry.
Ink renders the dashboard and setup wizard; commander drives ingest/report/replay/remedy. React 19 because Ink 6 requires it.
Reads opencode's DB through the sqlite3 binary, not a native module, behind an injectable SqlExec seam so the core stays dependency-free and the runner is mockable.
248 cases across 74 describe blocks; ingesters run against captured fixtures, and load-bearing invariants (no-I/O, sentinel-survives, fix==not-a-fix) are asserted directly.
Defense-in-depth after a real secret-leak incident: in-process scrubber at ingest, gitleaks at commit, CI scan in pipeline.
Three boundaries that hold it up
The architecture is legible as three hard boundaries, each enforced in code rather than convention:
- The schema waist. Source-aware parsing is strictly upstream of
safeParse. A regression in any ingester fails at the parser, in one place, not silently in the classifier three layers later. - The privacy boundary. Scrubbing happens at ingest, before anything persists. The remedy layer is gated to change-shaped evidence (path, action, line counts, a content
sha256) and never file content, an invariant enforced by a purity test that statically assertsremedy.tsimports nofs/child_process/netand never callsspawn(. - The execute boundary. The read surfaces never run an agent or touch the network. The demoted engine is the only component that spawns subprocesses, and it's firewalled from the observability core, which has zero native deps and runs under
npxanywhere.
The event model (low-level)
SessionEvent is a z.discriminatedUnion('kind', …) over 9 variants: user_message, agent_message, tool_call, tool_result, file_change, error, interrupt, subagent_spawn, and a session marker. A discriminated union is an algebraic sum type the compiler checks exhaustively, so a new event kind forces every switch to handle it. Every event extends a base carrying three things that matter:
const EventBaseSchema = z.object({
seq: z.number().int().nonnegative(), // monotonic per session
timestamp: z.string().datetime().optional(),
source: SourceRefSchema, // { kind, file, line?, byteOffset? }
});
Two deliberate choices live here. Ordering is the monotonic per-session seq, not timestamps. The in-file comment is blunt: clocks lie, and a resumed session can span days. Every event carries a SourceRef back to its origin artifact; the JSONL ingesters record the source line number, and the schema reserves a byteOffset for finer provenance, so a downstream consumer that disputes the parser can locate the decision in the original file. (The SQLite ingester records the database file but no row coordinate: a SQLite row has no line, which is one honest seam in the provenance story.) And file_change carries a contentSha256 of the new content, never the content itself, so "the agent rewrote the same file ten times identically" is detectable by hash without storing a single byte. That's content-addressing doing double duty: privacy and idempotency from the same field.
Scaling, honestly
Scaling is bounded by local disk and a linear digest scan, which is the right call for a single-user CLI, and I'll say plainly that it is O(n). listDigests() reads and re-validates every digest file on each report/replay/remedy call (199 files today). The mechanism that makes that fine is the fingerprint: it collapses an unbounded session count into a small bucket space. On the real store, 199 sessions collapse to 42 distinct fingerprints, with real mass: top buckets of 45, 25, 21, 11, 10. Digests drive the rollups; full traces are loaded lazily only for capped survivors (replay deep-loads at most 10, remedy hard-caps resolved samples at 3), so a huge bucket never blows memory. No concurrency control is needed because ingest is single-writer and reads are idempotent. The documented swap point if subprocess-per-query ever bites is the SqlExec seam: sqlite3 CLI → better-sqlite3, one interface, no consumer change.
The hard problems
How do you find a session that solved this when a failing bucket has zero successes in it?
This is the trap that nearly broke the premise, and it's the central low-level insight in the whole system. The point of a learning layer is to answer "for this failing pattern, which past sessions hit the same shape and later succeeded?" But the fingerprint is computed from the outcome:
fingerprint = sha256([
agentCli.name, outcome,
top3NonzeroErrorClassesSorted, // alphabetical → order-independent
bucketFailureRate(rate), // none | <20% low | <60% mid | ≥60% high
hasEditLoops ? 'loops' : 'no-loops',
].join('|')).slice(0, 16);
Because outcome is an input, a failing bucket contains zero completed siblings by construction. A same-bucket lookup is dead on arrival; there is nothing to compare against inside the bucket.
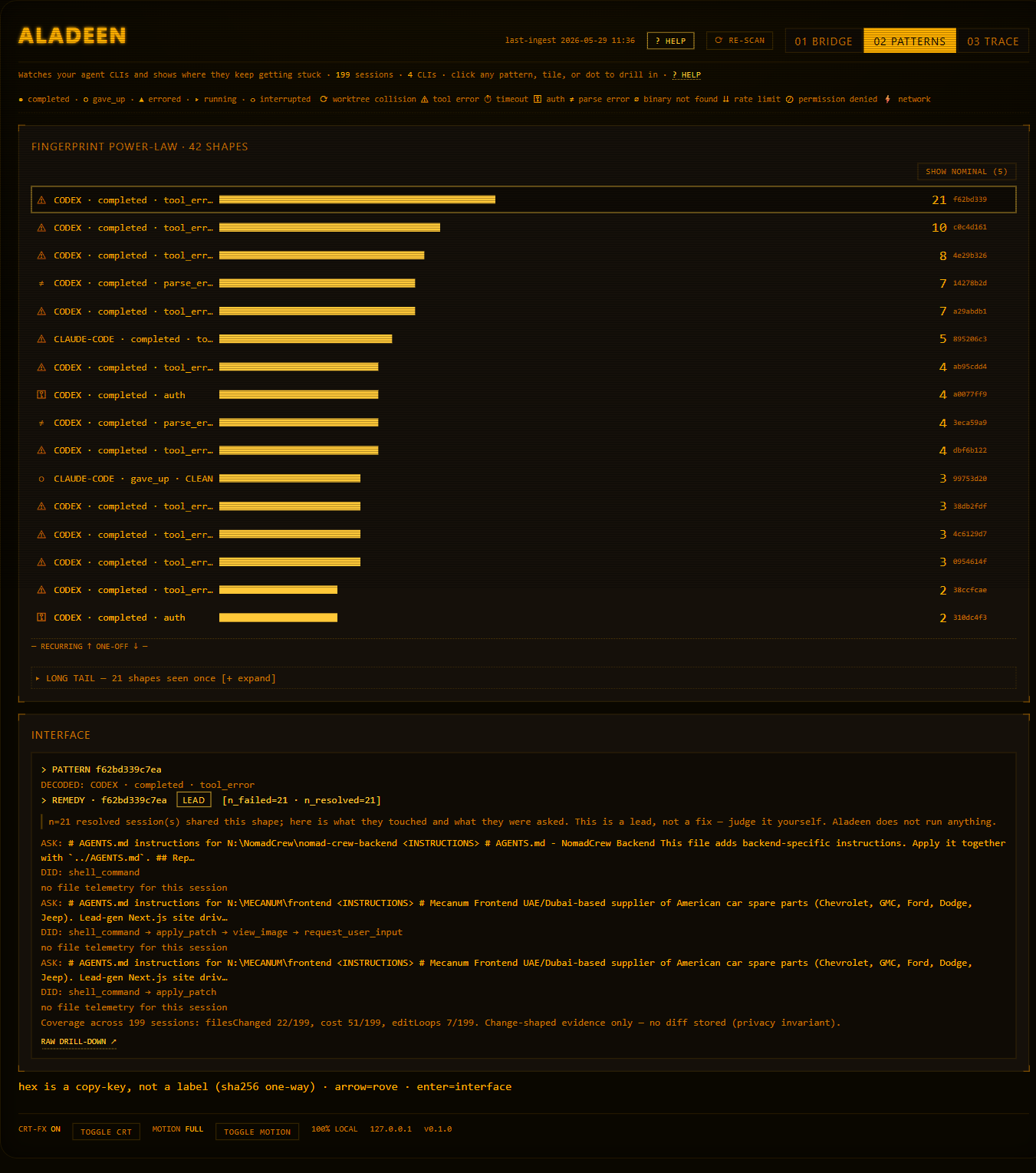
The fix is a separate cross-fingerprint join key. remedy.subSignature(d) derives ${agentCliName}|${sortedNonzeroErrorClasses} (deliberately dropping outcome, failure-rate, and loops) and returns '' as a suppression sentinel when there are no nonzero classes. Resolved siblings are completed sessions sharing that sub-signature. The subtle correctness bug underneath cost the feature: my first "resolved" gate was outcome === 'completed' && toolFailureCount === 0, and it made the entire evidence tier dead code. digest.ts increments errorCounts on fatal error events too, not only failed tool results, so a genuinely resolved session can finish completed while still carrying a non-empty error sub-signature. The stricter gate excluded exactly those sessions. Relaxing to completed alone is what made the tier fire at all. Sibling ranking sorts by error-class-set overlap descending, with a sessionId.localeCompare tiebreak the code annotates as deterministic but explicitly not recency. RunDigest has no startedAt, so calling it "most recent" would be a lie.
Recall over precision, stated out loud
Dropping failure-rate and edit-loops from the join key trades precision for recall: two sessions can share an error-class shape while differing in severity. That is exactly why the tier is labeled a lead, not a fix, and why it prints nFailed/nResolved denominators instead of a confidence percentage. The empirical backbone: of 199 sessions, only ~9 are failures (8 gave_up, 1 errored) with 1 more still running, and most gave_up sessions carry empty sub-signatures that correctly suppress to none.
Because the pattern fingerprint is computed from a session's outcome, a failing bucket contains zero successful sessions by construction. So the remedy engine joins across fingerprints on a sub-signature of (agent + sorted error classes) that deliberately drops outcome. That is the only way to find a session that hit this same shape and later succeeded.
How do you stop an AI suggestion feature from overclaiming on thin data?
The easy failure mode for any "AI suggestion" feature is overclaiming: one weak data point in, one confident remedy out. On a real store most fingerprint buckets are size 1, so the truthful answer is usually "I have nothing comparable." The engineering problem was making that impossible for cheerful prose to inflate: turning calibration into a state machine instead of a tone.
suggestRemedy is a gated cascade. Tier A fires when a failing bucket carries a rule's matchErrorClass and passes its extraGate. REMEDY_RULES is a two-entry data registry (worktree_collision; and lint_loop, whose extraGate requires editLoops.length > 0 so a lone tsc failure regexed as a lint loop can't assert a loop the data never proves). Then four short-circuit gates:
- Gate 0: non-failing bucket →
nonewithnFailed=0(a denominator must never count sessions that didn't fail). - Gate 1: empty sub-signature →
none. - Gate 2: zero resolved siblings →
none. - Otherwise tier =
nResolved >= 3 ? 'medium' : 'low'.
The part I'm proudest of is dumber than it sounds: guardrailFor() templates the guardrail string per tier, so the literal word "fix" appears only on the known-fix tier and inside the phrase "not a fix." A verb-discipline unit test renders the low and medium markdown and asserts count(/fix/gi) === count(/not a fix/gi) in each, mechanically proving the author cannot upgrade a suggestion by tone. A separate purity test reads remedy.ts and asserts it imports no fs/child_process/net module and contains no spawn( call, so "it never reads file contents" is enforced by the build, not promised in a comment. The evidence type is ChangeShapedFile { path, action?, linesAdded?, linesRemoved?, contentSha256? } (hash only, never content) and a hasFileTelemetry=false flag forces the UI to say the changeset is unknown rather than imply a clean one.
The README under-promises on purpose
It advertises only known-fix, low, and none, and hides the rare medium tier, because medium is uncommon on small stores and I'd rather ship a less impressive pitch than ever be caught inflating one. The on-disk numbers back the caution: worktree_collision has 2 live failing sessions carrying the known-fix class, and lint_loop is 0 of 199. A remedy you can't audit is just a confident guess.
The guardrail strings are templated per confidence tier, so the literal word "fix" can only appear on the rule-encoded known-fix tier. You cannot upgrade a suggestion by tone. And every result prints its nFailed/nResolved denominators, because a remedy you can't audit is just a confident guess.
How do you make a JSONL stream and fused SQLite rows emit byte-identical output?
Claude Code and Codex write append-only JSONL where each line is a typed record and a tool call and its result are separate lines paired by id. opencode stores everything in a relational SQLite DB across session, message, and part tables, and fuses a tool call and its result into one part row whose state.status (pending/running/completed/error) says whether a result even exists yet. A naive normalizer either leaks the storage shape into the schema or hallucinates results for calls that haven't finished. Both paths must produce a byte-identical SessionTrace.
The opencode ingester always emits a tool_call from the part, but emits a tool_result only when status is terminal (completed or error, never running/pending). The load-bearing line is opencode.ts:274; mid-flight calls would otherwise hallucinate a phantom result. Cost is rolled up from message.tokens; a message-level data.error (a provider/model turn failure, distinct from a tool's own state.error) is hoisted into a synthetic fatal error event that feeds outcome inference. The Claude Code ingester does the inverse: it keeps a callIndex Map from tool_use_id to {toolName, args} to pair results back across lines and synthesize file_change events from successful Edit/Write tools. Two storage models, one output, validated identically:
const parsed = SessionTraceSchema.safeParse(trace);
if (!parsed.success) { /* regression fails HERE, at the boundary */ }
A subprocess instead of a native module, and the injection surface it opens
Reading SQLite via the sqlite3 CLI keeps the core dependency-free but adds a runtime requirement (sqlite3 on PATH, checked at preflight) and one subprocess per query batch. It also forces string-interpolated SQL (the CLI has no parameter binding), a real injection surface. The mitigation is sqlQuoteId(), which doubles single quotes on ids that the schema bounds to ses_/msg_ alphanumerics: a small, named threat with a stated countermeasure rather than an unexamined one. The injectable SqlExec seam exists precisely so I can swap in better-sqlite3 later without touching ingest logic, and so the subprocess is mockable today.
Exit code zero means nothing: outcome inference as a rule cascade
No agent CLI reliably tells you whether a session succeeded. An agent can stall mid-tool-call, get interrupted, or bomb on a run of failing tools and still quit clean. So outcome is inferred, never read from a flag, by a shared inferOutcome(events, ctx) that applies seven ordered rules, earlier wins:
- source mtime < 5 min →
running - saw interrupt →
interrupted - saw fatal error →
errored - trailing
tool_resultswhere the tail (last up-to-5, minimum 3) is ≥80% failures and the last one failed →errored("silently bombed") - dangling open
callIds: walk the stream maintaining anopenCallsSet, add ontool_call, delete ontool_result, anything left →gave_up - any
user_messageortool_callpresent →completed - else →
unknown
The schema keeps unknown as a first-class outcome rather than forcing a guess. Promoting this to a shared module fixed a real bug: Codex's earlier inline copy omitted the mtime and interrupt branches, so recent live sessions misclassified as completed. (A precision note the earlier draft of this study got slightly wrong: rule 4 is "last up-to-5, minimum 3," not a flat "last five": tail.length >= 3 && fails / tail.length >= 0.8 && !lastResult.ok.)
The engine I demoted is a crash-resumable DAG state machine, and it broke in three instructive ways
I kept the blueprint runner only as a training-data source, but it's the single largest piece of system-design substance here, so it earns a section. BlueprintRunner.walk is a dynamic edge-following walker, explicitly not a topological sort, so feedback loops (lint → fix → lint) are first-class rather than a graph-cycle error. Per-node NodeExecution is a finite state machine (pending → running → completed | failed); the run itself has six states (pending, running, completed, failed, escalated, abandoned). State is persisted after every node, making runs resumable via resume(). A wall-clock timeout routes to escalated. Three bugs came out of real dogfood runs:
- A runaway retry loop. A deterministic lint→fix→lint loop ran between 1,930 and 2,267 node attempts before tripping any budget, because there are two retry budgets (per-node
maxRetriesand a globaltotalRetriesvsmaxTotalRetries) and the global counter was only bumped on the agentic path. The fix bumps it on every node re-entry (exec.attempts > 0), so the global cap actually sees a deterministic loop. - A default edge that bypassed a verifier.
resolveNextgives default edges to onlysuccessandfailure. The agentic executor downgradessuccess → retryprecisely whengit status --shortshows no file changes (therequiresFileChangesguard against an agent claiming completion while doing nothing). Aretrywith no expliciton:'retry'edge had been falling through to the default success edge: advancing the run and bypassing the verifier, the exact silent-hallucination-of-completion the guard existed to stop. Now aretrywith no retry edge re-executes the same node (resolveNextreturnsnull). - Orphaned "running" state. This is the most distributed-systems-literate of the three, and the earlier study missed it entirely. Persisted runs sat at
status: 'running'for weeks after the process was killed, because there was no liveness signal for a fresh process to detect an orphan. The fix adds theabandonedterminal state andStatePersistence.sweepStale(), which flipsrunningrecords older than ~2×maxRunDurationMstoabandonedon list-runs: garbage collection of stale state, the local-store cousin of a heartbeat-and-reap loop. When those runs are later ingested,abandonedmaps to agave_upoutcome.
Restricting default edges costs verbosity, buys correctness
Limiting default edges to success/failure means every retry loop must be wired explicitly in the blueprint's edge list: more verbose graphs. In exchange it eliminates a whole class of "the agent did nothing yet the run passed" false positives. The completion side makes the matching call: in headless mode, process exit is the completion signal (no PTY parsing, no quiescence heuristics), a determinism argument. The documented PTY-quiescence fallback names its own failure modes (false-positive while the agent is "thinking," false-negative on bursty output, prompt-regex breaking on a CLI UI update), which is why it's the strategy of last resort.
A worktree teardown that silently deleted the main repo's node_modules
To run quality gates (tsc, lint, test) inside an isolated git worktree, you need node_modules there, and git worktree add doesn't copy it. So I junctioned the main repo's node_modules into each worktree. That fixed the "tsc can't find typescript" loop and introduced a far nastier one: on Windows NTFS, a recursive delete, including git worktree remove --force, descends into a junction and deletes the link target. Tearing down a worktree emptied the main repo's dependencies and forced a full npm install to recover.
The countermeasure is detachLinkedDeps(): before any removal it lstats the worktree's node_modules and, if it's a symlink/junction, unlinks the link first so the subsequent recursive delete can't follow it (the CRITICAL ordering comment lives at worktree.ts:175-188; remove() calls detachLinkedDeps before git worktree remove). The ordering is the whole fix, locked in by a regression test that plants node_modules/fake-pkg/index.js and asserts the sentinel survives a full create→remove cycle. Two confinement invariants back it: a worktree is only managed if its branch starts with aladeen/ and its normalized path is under the managed root: "only destroy what we own."
On NTFS,
git worktree remove --forcefollows a junction and deletes its target. The first time I junctioned node_modules into a worktree to make tsc work, tearing that worktree down emptied the main repo's dependencies. Now a regression test plants a sentinel file in a fake node_modules and asserts it survives a create-then-remove cycle.
The fundamentals, by name
A staff reviewer scans for whether the code demonstrates CS fundamentals or just name-drops them. These are the ones the code genuinely shows, each with where it lives:
- Normalization / canonical model. The schema waist projects five stores onto one validated
SessionTrace; source-aware code is strictly upstream ofsafeParse. - Algebraic sum type + open taxonomy.
SessionEventis a closeddiscriminatedUnionthe compiler checks exhaustively;ERROR_CLASSES(13) is a deliberately open taxonomy, and the classifier runs domainextraClassesbefore built-ins so specific rules shadow the generictool_errordefault without polluting shared patterns. - Idempotency + content-addressing + determinism.
RunDigestis "always regeneratable" from a trace; re-ingesting the same source yields the same stablesessionIdand a strictly-better trace under a versioned scrubber.file_changecarries acontentSha256so identical rewrites are detectable without storing bytes. Ordering is monotonicseq, not timestamps. - Data minimization / privacy-by-design + defense-in-depth + threat modeling. Scrubbing at the ingest boundary before persistence; remedy gated to change-shaped evidence, enforced by a purity test. Three independent secret layers after a real incident. A named threat model in code: the
crossSpawncall in the headless runner is wrapped in a try/catch tagged as defense against CVE-2024-27980 (Node 20.12+ rejecting.cmd/.batwithoutshell:true), so a spawn-time throw surfaces as a result instead of corrupting run state. - Liveness / orphaned-state reclamation.
sweepStale()+ theabandonedterminal state: garbage collection of stale runs on a local store. - Backpressure / bounded work. Reads never load unbounded data: replay deep-loads ≤10, remedy hard-caps samples at 3, the scrubber truncates output at 2000 chars with a
[REDACTED:shell-output truncated N chars]marker, replay excerpts cap at 200 chars. - Dependency-injection seams. Every external dependency is injectable (
SqlExecfor the sqlite3 subprocess,IngestStorage, the git-status probe in the agentic executor, theScrubberin every ingester), which is what lets 248 tests run hermetically and lets the load-bearing invariants be asserted directly.
By the numbers
Real counts from the repo and the on-disk store, measured, not projected:
| Metric | Value | What it means |
|---|---|---|
| Non-test TS source | ~10.5k lines | The observability core plus the demoted engine. |
| Tests | 248 cases / 74 describe blocks | Ingesters run against captured fixtures; invariants are asserted, not assumed. |
| Log stores → schema | 5 sources / 2 storage shapes | Claude Code, opencode, Codex, OpenClaw, aladeen-runs → one SessionTrace. |
| Event kinds | 9 | The discriminated union every ingester targets. |
| Dogfood store | 199 sessions | 139 codex, 40 claude-code, 12 opencode, 8 aladeen-runs (read from agentCliName in each digest). |
| Fingerprint buckets | 42 | 199 sessions collapse to 42 distinct fingerprints; top buckets 45/25/21/11/10. |
| Outcome distribution | 189 / 8 / 1 / 1 | completed / gave_up / running / errored: only ~9 failures, the backbone for under-promising. |
| Headless adapters | 6 | claude, codex, gemini, opencode, local-ollama, local-llama-cpp (gemini/local wired but less exercised). |
| SourceKinds | 7 (5 implemented) | gemini/hermes are declared in the union but roadmap-gated, not built. |
aladeen 0.1.0 is published to npm with bins aladeen and aladeen-mcp (npm view aladeen version → 0.1.0, dist-tags.latest → 0.1.0), matching package.json.
Two numbers carry their consequence with them. The worktree-deps fix turned an infinite hang into a 1.8s end-to-end success (validation run 27d5e8f8, fix commit 99b76d4). And the runaway deterministic loop ran 1,930–2,267 node attempts (runs 690cbbfe, b9428fa6) while totalRetries stayed at 0: the entire argument for incrementing the global budget on every re-entry, not just the agentic path.
What was hard / what I'd change
The honest spine of this project is that the interesting bugs only showed up after the obvious fixes, and the codebase is unusually candid about it. There's an append-only postrun learnings.md that reads like a flight recorder: run IDs, commit hashes, before/after timings. That file is the single most credibility-building artifact in the repo, because it records the failures, not just the wins: the three engine bugs above each trace to a dated entry in it.
The empirical validation I'm most glad I did is the fingerprint's. The v2 fingerprint dropped per-session file extensions and bucketized failure-rate instead, because v1's extension dimension made every bucket size 1 on real data: each session touches a unique file mix, so the key was unique for an irrelevant reason. I didn't have to take that on faith: the live store collapses 199 sessions to 42 buckets with real mass (45/25/21/…), which is direct proof the v2 decision fixed v1's degeneracy. The cost is honest too: coarser keys lose file-level locality, so two sessions can share a fingerprint while touching entirely different files, which is why replay surfaces per-bucket file aggregates and the remedy tier prints denominators.
What I'm leaving honest in the open: OpenClaw is fixture-validated, with a real-vault smoke test still pending. The store contains zero OpenClaw-named sessions, so that hedge stays. The scrubber is the place I'd most want to raise my own honesty: it declares six redaction reasons behind a versioned envelope but run() actually applies only three today (secret, home-path, output-truncation); pii/env-value/file-content are declared-but-not-yet-wired passes, and manifest() reports exactly the three it applies. Stating "three passes today behind a six-reason versioned envelope built for more" is both accurate and the point of the versioning design. The Gemini and Hermes source kinds are declared in the union but unimplemented: roadmap, not capability. And the outcome classifier's thresholds (last-up-to-5, 80%, 5-minute mtime) are hand-picked heuristics tuned on early data; they earn their keep, but they're the part I'd most want to learn from a larger store rather than hand-set.
FAQ
Why not just use an orchestrator like Conductor or Vibe Kanban?
Those drive the agent. Aladeen does the opposite: it never runs your agent, it reads the logs your agent already writes to disk and mines them for recurring failure shapes. The orchestrator category is saturated; observability for CLI-based agents was essentially empty. Aladeen actually started as an orchestrator and was deliberately demoted. The runner survives only because its own execution traces are a fifth ingestible source, which closes an observability loop on the engine itself.
How do you normalize a JSONL log and a SQLite database into the same schema?
A Zod SessionTrace, a discriminated union over 9 event kinds with a monotonic per-session seq and a SourceRef back-pointer on every event, is the fixed waist every ingester targets. The Claude Code ingester pairs tool_use to tool_result across separate JSONL lines via a callIndex map; the opencode ingester reads a relational SQLite store where a call and its result share one row, and splits it into two events, emitting the result only when the row status is terminal. Every trace is safeParse-d at the boundary, so a schema regression fails at the parser, not at three consumers downstream. Source-aware code lives strictly upstream of that parse; everything below it is source-blind.
Why read SQLite through a subprocess instead of a native module?
To keep the core observability path pure-JS with zero native dependencies, so `npx aladeen report` runs anywhere Node 20+ does with no compile step: the dominant constraint for a zero-budget solo CLI. opencode's DB is read via a `sqlite3 -readonly -json` subprocess behind an injectable SqlExec seam, which makes it mockable in tests and swappable for better-sqlite3 later. The cost is a runtime dependency (sqlite3 on PATH, checked at preflight) and string-interpolated SQL, since the CLI has no parameter binding, a small injection surface mitigated by quoting ids that are bounded to ses_/msg_ alphanumerics.
How does the remedy engine find a session that solved a failure when the fingerprint bakes in the outcome?
It can't use a same-bucket lookup: because outcome is an input to the fingerprint, a failing bucket contains zero successful sessions by construction. So the remedy engine joins across fingerprints on a sub-signature of (agent + sorted error classes) that deliberately drops outcome, failure-rate, and edit-loops, then keeps any completed session sharing that signature as a resolved sibling. It trades precision for recall on purpose, which is why the result is labeled a lead, not a fix, and prints its nFailed/nResolved denominators instead of a confidence score.
What stops the remedy engine from overclaiming on thin data?
Four hard short-circuit gates and per-tier templated language. A non-failing bucket returns none with nFailed=0; an empty sub-signature suppresses to none; zero resolved siblings returns none; medium requires at least 3 resolved siblings or it downgrades to low. The guardrail string is templated per tier so the literal word "fix" can only appear on the rule-encoded tier. A unit test asserts the count of "fix" equals the count of "not a fix" in the lower-tier markdown, which mechanically proves you cannot upgrade a suggestion by tone. On a 199-session store where most buckets are size 1, the honest answer is usually "I have nothing comparable."
How does a running agent query this mid-session?
Aladeen ships an MCP server (aladeen-mcp) over stdio with three read-only tools and two resources, wired in with one .mcp.json entry. Each tool returns both human-readable markdown and a machine-actionable structuredContent payload (tier, sub-signature, denominators, rule citations, change-shaped evidence) so a calling agent acts on the data without scraping prose, and isError is wired to empty result sets as a real tool-error contract. It never touches the network and never launches an agent CLI; the connected agent stays the actor.
Most "AI insight" tools fail the moment they should say "I don't know." Aladeen makes that the cheapest path through the code, and proves it with a test that counts the word "fix."